데이터를 말아올리는 대표적인 방법 - Message Queue
이 글을 쓰는 이유
크게 두 가지 목적에 의해 이 글을 작성하게 되었다.
1) 데이터를 말아 올리는 대표적인 방법 4가지 중에서 많이 사용되는 MQ에 대해서 개념, 솔루션 종류를 알아본다.
2) 요즘 클라우드 환경으로 전환됨에 따라 많이 사용되며 개인적으로도 관심이 있는 카프카에 대해 개념을 알아본다.
한 번에 처리해야할 데이터가 굉장히 많거나, 어떤 두 프로그램 간에 커뮤니케이션이 원활하지 않거나와 같은 여러 이유로 실시간 통신이 제대로 작동하지 않는 경우 우리는 비동기식 통신(Asynchronous Communication)을 고려할 수 있다. 그 방법에는 크게 MQ, Jenkins, Lambda, Spring Batch까지 총 4가지가 있다.
1. MQ (Message Queue)
애플리케이션을 비동기식 통신으로 분리해야할 경우 사용하는 메시지 기반의 미들웨어로 여러 시스템, 서비스 간의 연결도 지원하는 솔루션이다.
MOM(Message Oriented Middleware)를 구현한 솔루션으로 비동기 메시지를 사용하는 서비스들 사이에서 데이터를 교환해주는 역할을 한다.
Producer(sender)가 메시지를 큐에 전송하면 Consumer(receiver)는 큐에서 메시지를 가져오면서 처리한다.
MQ는 producer와 consumer에 message 프로세스가 추가되는 것이 특징이다.
MQ를 사용하여 비동기로 요청하고, 처리하고자 하는 서비스들을 분리하여 사용할 수 있다.
1-1. 관련개념
Message
전송되어야 할 데이터를 우리는 메시지라고 부르며 데이터 포맷의 유형이기도 하다.
Queue
가장 간단한 형태의 큐는 순차적으로 처리되는 일련의 요청들을 가리킨다. 이런 일련의 요청들에 대한 처리를 위해서는 무엇을 알아야 할지 생각해보면 가장 먼저 요청받은 메시지를 알고, 대기열이 어느 정도있는지도 알고 있어야 하고, 전체적으로도 알고 있어야 한다.
- 모든 사람들이 매일 사용하는 도구, 이메일
- 이메일은 비동기 통신이 어떻게 동작하는지 알 수 있는 완벽한 예다.
- 큐에 대한 이론을 실제 우리의 생활에 적용해볼 수 있다.
- A가 네이버 메일에서 메시지를 보내면, B는 받은 편지함에 들어오는 답장을 기다릴 수 있다.
- 발신자: A / 수신자 : B
- 여기서 B의 이메일의 받은 편지함을 거기에 보관되어 있는 메시지의 대기열이라고 생각해보자.
- 그리고 어떤 시점에 A가 보낸 메일을 B는 받을 것이고, 그가 원할 떄 언제든지 메일을 읽을 수 있다.
- 시간이 더 오래 지날 경우, B가 읽어야 하는 메시지의 목록은 더 많아져 있을 것이다
나의 네이버 메일도 잠깐 확인 안하면 메일들이 엄청 쌓여있다. 근데 약간 비동기의 예시라고 하기에 조금 현실과 동떨어지는 부분이 있는데, 그건 바로 일반적으로 이메일을 다 확인하지 않고 일부만 열어본다는 것이다.
예를 들어서 내가 메일을 쓰고 그에 대한 답장을 기다리는 경우에 대해서만 메일함을 계속 들여다보거나 관련 없는 메일도 읽어보는 것 같다. 다른 사람들도 이런 경우가 아니면 대개 받은 메일함을 대충 한 번 보고 넘기지 않나…? 물론 이메일 하나하나 다 열어보고 확인하는 사람도 있겠지만 나처럼 내가 이메일을 쓰고 답장이 오기를 기다릴 때만 다 읽어보는 사람이 대부분 일 것이다. 그래서 위와 같은 이유로 큐의 개념인
들어오는 요청을 순차적으로 다 처리한다
라는 개념과 이메일의 현실에서는 조금 차이가 있긴 하지만…! 그래도 이메일은 비동기를 현실 세계에 비유할 수 있는 가장 적절한 예시다. 그 이유는
- 이메일을 아무때나 작성하고 보낼 수 있다. 수신자가 내 메일을 받았는지, 언제 대답할 예정인지에 대해서 따로 걱정하고 계획하지 않아도 된다.
그럼 이제 큐가 뭔지 알겠다. 그럼 실제로 큐가 어떤식으로 사용되는지 사용사례를 알고, 그 사용 사례를 통해 Message의 유형에 대해서도 알고 싶다. 큐는 메시지의 줄, 즉 대기열이다. 여기서 메시지를 보내는 사람을 Producer이라하고, 받는 사람을 Consumer라 한다.
메시지 큐의 장점
- 비동기(Asynchronous): 큐에 넣기 때문에 나중에 처리할 수 있다.
- 비동조(Decoupling): 애플리케이션과 분리 가능하다
- 탄력성(Resilience): 일부가 실패해도 전체에 영향을 받지 않는다.
- 과잉(Redundancy): 실패할 경우 재실행이 가능하다
- 보증(Guarantees): 작업이 처리된 것을 확인할 수 있다.
- 확증성(Scalable): 다수의 프로세스들이 큐에 메시지를 보낼 수 있다.
큐는 위와 같은 장점으로 인해 대용량 데이터를 처리하기 위한 배치 작업이나, 채팅 서비스, 비동기 데이터를 처리할 때 사용한다.
MOM(Message Oriented Middleware): 메시지 지향 미들웨어
- 분산 시스템 간 메시지를 주고 받는 기능을 지원하는 소프트웨어나 하드웨어 인프라
프로토콜
AMQP(Advanced Message Queuing Protocol)
이기종 플랫폼 간의 상호 메시지 교환 가능하며, 특히 클라우드 컴퓨팅 환경에 매우 적합하다.
AMQP는 금융계의 이기종 플랫폼 간의 메시지 상호 정보 교환을 위해서 JPMorgan의 John O’Hara에 의해 개발되었으며 2006년도에 최초 사용되었다고 한다.
AMQP working Node group에 의해 개발된 오픈 스펙이다.
구현 소프트웨어 예시 : RabbitMQ
- Subscribe to have messages delivered to them (“Push API”): this is the recommended option.
- Polling(“Pull API”): 이 방법은 매우 비효율적이고 대부분의 경우에서 피해야 할 방법이다.
즉, Push와 Pull 방식 모두 가능하나 push를 권장하고 있다.
이 외에도 StormMQ, Apache Qpid와 같은 오픈 소스 구현 브로커가 있다.
JMS(Java Messaging System)
자바 플랫폼 간의 상호 메시지 교환이 가능하다. 단, 이기종 플랫폼 간은 제한적이다.
RabbitMQ 문서를 보면 클라우딩 컴퓨팅 또는 Social Service 환경에서 처럼 대용량 메시지 처리는 AMQP가 적합하다.
구현 소프트웨어 예시 : Active MQ
- ActiveMq does not support the AMQP protocol. and it does not select the consumer. because JMS is basically a pull system from receiver perspective. the broker does not push (Consumer에서 pull하는 방식으로 처리한다)
메시징 모델
- JMS는 publish-subscriber, point-to-point 메시징 모델을 제공한다.
1-2. 메시지 플랫폼
메시지 플랫폼은 크게 두가지 종류로 나뉘어진다. 첫 번째는 메시지 브로커, 두번째는 이벤트 브로커이다.
메시지 브로커는 이벤트 브로커로 역할을 할 수 없지만, 이벤트 브로커는 메시지 브로커 역할을 할 수 있다.
메시지 브로커(Message Broker)
- 메시지 브로커는 많은 기업들의 대규모 미들웨어 아키텍처에서 사용되어 왔다.
- 미들웨어: 서비스하는 애플리케이션들을 보다 효율적으로 아키텍처들을 연결하는 요소로 작동하는 SW
- ex) 메시징 플랫폼, 인증 플랫폼, DB
- 미들웨어: 서비스하는 애플리케이션들을 보다 효율적으로 아키텍처들을 연결하는 요소로 작동하는 SW
- Producer(송신자)와 Consumer(수신자)를 통해 메시지를 통신하고 네트워크를 맺는 용도로 사용해왔다.
- 특징
- 데이터를 보내고 처리하고 삭제함
- 메시지를 받아서 적절히 처리하고 나면 즉시 또는 짧은 시간 내에 삭제되는 구조
- EX) Redis Queue, Rabbit MQ, Apache Kafka, ZeroMQ, AWS SQS, Azure Service Bus, Apache ActiveMQ, IBM MQ
| 보내는 쪽 | Sender | Producer | publisher |
|---|---|---|---|
| 받는 쪽 | Receiver | Consumer | subscriber |
이벤트 브로커
- 이벤트 또는 메시지라고 불리는 레코드를 딱 하나만 보관하고 인덱스를 통해 개별 액세스를 관리함
- 업무상 필요한 시간 동안 이벤트를 보존 가능
- 메시지 브로커와 달리 데이터를 삭제하지 않음
- 서비스에서 나오는 이벤트를 마치 DB에 저장하듯이 이벤트 브로커의 큐에 저장함
- 딱 한번 일어난 이벤트 데이터를 브로커에 저장함으로써 단일 진실 공급원으로 사용 가능
- 장애가 발생했을 때 장애가 일어난 지점부터 재처리 가능
- 많은 양의 실시간 스트림 데이터를 효과적으로 처리 가능
- 이 외에도 다양한 이벤트 기반 MSA에서 중요한 역할을 처리함
- 이벤트 브로커로 클러스터를 구축하면 이벤트 기반 MSA로 발전하는데에 중요한 역할을 하며, 메시지 브로커로도 사용할 수 있음
- EX) Kafka, AWS의 키네시스
2. MQ 대표 솔루션
2.1 대표적인 이벤트 브로커, kafka

카프카란?
- 분산 이벤트 스트리밍 플랫폼
- 프로듀서/컨슈머 분리
- 메시지 데이터를 여러 컨슈머에게 허용
- 대용량, 대규모 메시지 데이터를 빠르게 처리할 수 있는 메시징 시스템
- 고성능 : 높은 처리량을 위한 메시지 최적화
- 무중단 스케일 아웃 가능 → 카프카의 클러스터를 만든 뒤에 데이터가 많아지면 스케일 아웃해야하는데, 이때 무중단으로 가능
- 관련 생태계 제공
- 포춘 100개 기업 대상으로 80프로 이상이 kafka를 사용하고 있음
- 국내에서도 우리가 아는 큰 회사들은 kafka를 많이 사용하고 있음
- 대용량, 대규모 메시지 데이터를 빠르게 처리할 수 있는 메시징 시스템
- 링크드인에서 시작했으나 → 현재는 아파치 공식 오픈소스
- 데이터 처리를 여러 어플리케이션에서 하는 것이 아니라 중앙의 한 곳에서 처리할 수 있도록 중앙 집중화되었음
- 애플리케이션, 웹사이트, 센서 등에서 취합한 데이터 스트림을 한 곳에서 실시간으로 관리할 수 있게 됨
- 기업의 대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있게 만들어줌
MQ 미사용/사용 웹 서비스 구조의 예시
- 어플리케이션과 데이터 베이스의 동기적 직접 통신 구조

어플리케이션과 DB가 강하게 결합되어 있어 어플리케이션의 요청&응답 과정에서 DB 서버로의 요청&응답 모두 완료되어야 응답이 가능하다.
따라서 다음과 같은 문제가 발생 가능하다.
- DB의 응답 시간이 길어진다면 어플리케이션 또한 그만큼 응답시간이 길어진다.
- DB 장애시 어플리케이션이 동작하지 못한다.
- 어플리케이션 입장에서 감당할 수 있는 요청의 수가 DB에서는 감당이 불가능하다면, 성능저하 또는 장애가 발생할 수 있다.
- MQ를 통한 어플리케이션과 DB의 통신

- 어플리케이션이 요청을 보내고, DB의 응답을 기다리지 않고 응답을 보낼 수 있다.
- DB는 큐의 요청을 꺼내 처리한다.
- DB 장애가 발생해도 어플리케이션은 독립적으로 동작 가능하다.
- 어플리케이션과 DB 사이의 통신을 처리량에 따라 제어 가능하다.
카프카는 왜 많이 사용되고 있을까?
1) High throughput message capacity
짧은 시간내에 엄청난 양의 데이터를 컨슈머까지 전달할 수 있다. 파티션을 통한 분산처리가 가능하기 때문에 데이터의 양이 많아질수록 Consumer 갯수를 늘려서 병렬처리가 가능하다. 이를 통해 데이터 처리를 더욱 빠르게 할 수 있다.
2) Scalability와 fault tolerant
확장성이 뛰어나다. 이미 사용되고 있는 카프카 브로커가 있다 하더라도 신규 브로커 서버를 추가해 수평확장이 가능하다. 그리고 브로커 중 몇대가 죽는다 하더라도 이미 replica로 복제된 데이터는 안전하게 보관되어있어 복구가 가능하다.
3) Undeleted log
다른 플랫폼과 달리 카프카 토픽에 들어간 데이터는 컨슈머가 데이터를 가져간다 하더라도 사라지지 않는다. 만약 다른 플랫폼에서 이러한 처리를 하려고 했다면 복잡한 방식을 썼어야 했겠지만, 카프카에서는 컨슈머의 그룹id만 다르면 동일한 데이터도 각각 다르게 처리가 가능하다.
그럼 카프카는 대규모 데이터 처리가 발생하는 곳에서만 쓰는 것이 좋을까? 아니다. 스타트업도 사용하면 좋다. 스타트업의 경우는 빠른 확장성과 안정성을 중요시 하는데, 카프카를 이용하면 빠른 Scale out이 가능하다.
카프카 클러스터 내부의 브로커 개수를 늘려서 원활하게 데이터 처리가 가능하다. 즉 어떤 형태의 기업에서도 적용이 가능하다.
탄생 배경
2009년 당시 링크드인에는 두 가지 이슈가 있었다고 한다. 첫 번째 이슈는 ‘데이터 중앙 저장소가 무엇인가?’였다.
현재는 DW를 사용하는 것이 익숙하지만 그때까지만 하더라도 Hadoop도 없었고, 빠르게 대응할 수 있는 SQL DB도 없었다. 때문에 그들은 모든 데이터에 빠르게 접근하기 위한 방법을 찾아야 했다.
그와 동시에 두 번째 이슈는 다양한 데이터 소스가 존재한다는 것이다. 사용할 데이터로 이루어진 DB 뿐만 아니라 Application, 이벤트, 네트워크 핑까지 수집했다. 이런 다양한 데이터들을 수집하다보니 어떻게 이 통합해야 하는지에 대한 고민에 직면했다.
그래서 그들은 데이터와 애플리케이션을 전체적으로 보는 데에 집중했다. Application은 DB나 Queue를 사용했었고, 데이터는 ETL 툴이나 Analytics툴을 사용했다. 즉, 애플리케이션과 데이터간에 시각화의 차이가 있었다.
하지만 그들은 새로운 것을 만들어내고 싶진 않았고, 이미 있는 것들을 조합하여 돌아가게 만들어보고 싶었다. 그래서 rabbitMQ, retrofit, ETL툴을 조합하여 사용했다. 그런데 사용하면 할수록 문제의 핵심을 해결하지 못한다는 느낌이 들었다고 한다. 그래서 만들게 된 것이 바로 카프카이며 2011년 초에 오픈소스화 되었다.
기본구조
카프카는 4개의 구성요소로 이루어져 있다.
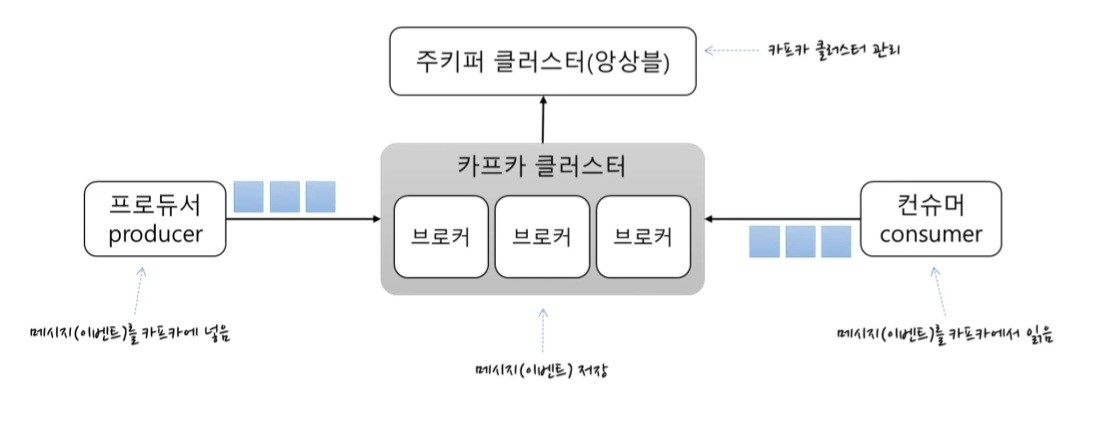
- 카프카 클러스터
- 메시지를 저장하는 저장소
- 하나의 카프카 클러스터는 여러개의 브로커로 구성되어 있음(보통 3대 이상의 브로커로 클러스터를 구성)
- 브로커는 각각의 서버라도 보면됨
- 브로커들이 메시지를 나눠서 저장하고, 이중화 처리하고, 장애 발생 시 대체도 함
- 데이터를 이동하는데에 핵심 역할을 맡음
- 1.1 Kafka broker
- 주로 실행된 카프카 애플리케이션 서버 중 1대를 운영함
- 주키퍼와 연동을 해야함( ~2.5.0버전 )
- 주키퍼의 역할: 메타데이터(브로커 id, 컨트롤 id 등) 저장
- 추후 주키퍼를 걷어낼 예정이라고 함
- n개 브로커 중 1대는 컨트롤러(Controller) 기능 수행
- 컨트롤러: 각 브로커에게 담당 파티션 할당 수행
- 주키퍼 클러스터
- 카프카 클러스터에 대한 정보를 기록 및 관리하는 용도
- 프로듀서: 카프카 클러스터에 메세지를 보내는 것
- 컨슈머: 메시지를 카프카에서 읽어옴
토픽과 파티션
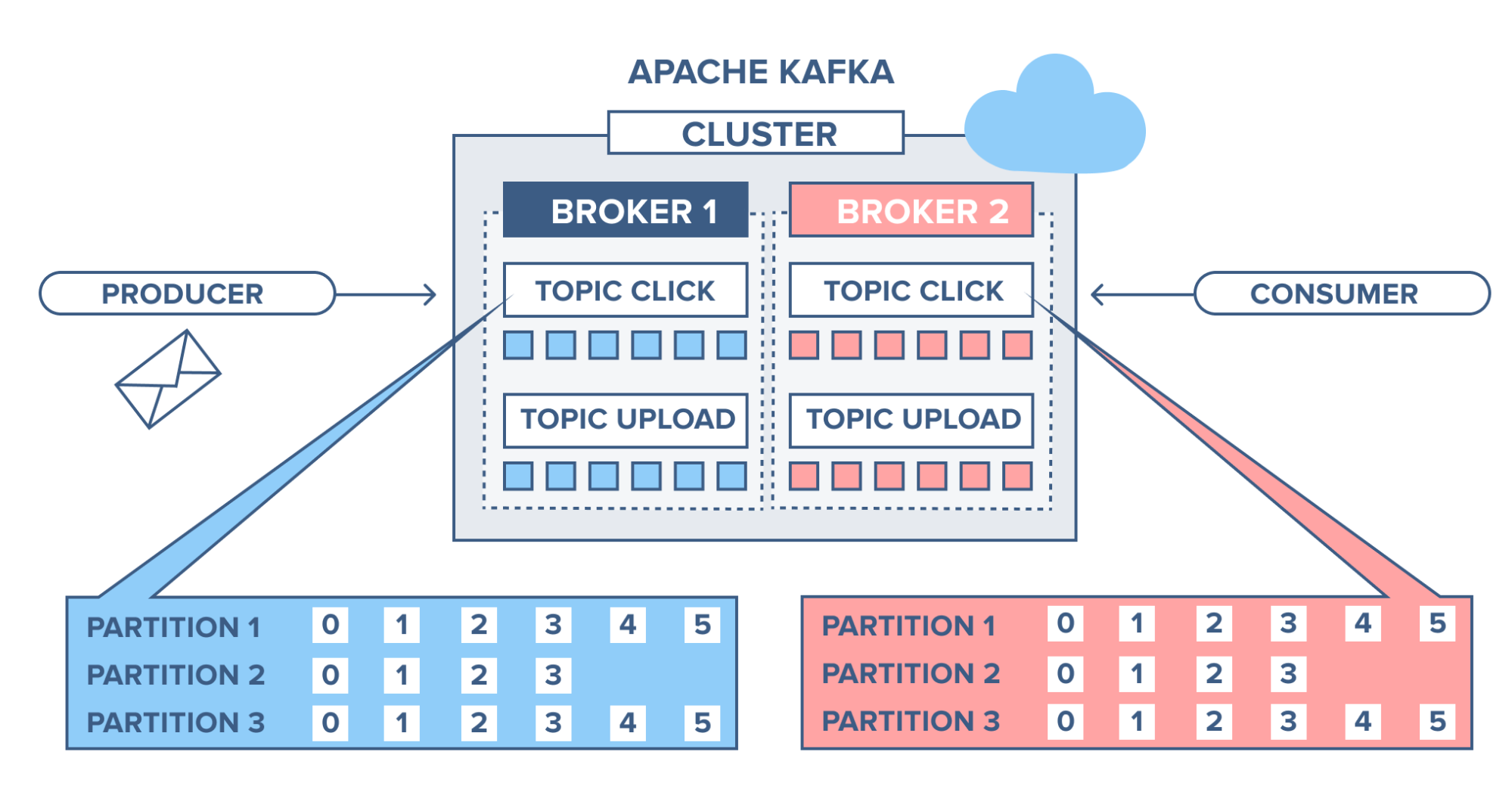
- 메시지를 구분하는 단위
- 뉴스용 토픽, 주문용 토픽
- 파일시스템의 폴더와 메일함과 유사
- 토픽은 1개 이상의 파티션으로 구성
- 파티션: 메시지를 저장하는 물리적인 파일
- 프로듀서와 컨슈머가 토픽을 기준으로 메시지를 받게됨
- 파티션에는 프로듀서가 보낸 데이터들이 들어가 저장되는데 이 데이터를 레코드라고 한다.
파티션과 오프셋, 메시지 순서
- 파티션은 추가만 가능한(append-only) 파일
- 오프셋: 각각의 메시지가 저장되는 위치
- 프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가
- 컨슈머는 오프셋 기준으로 메시지를 순서대로 읽음
- 파티션에 저장된 메시지는 컨슈머가 읽었는지와는 상관없이 삭제되지 않음
- 여러 파티션과 프로듀서
- 라운드로빈 또는 키로 파티션을 선택함
- 프로듀서가 카프카에 메시지를 전달할때 선택 가능
- 같은 키는 메시지 순서가 유지됨
- 여러 파티션과 컨슈머
- 컨슈머가 카프카 브로커에 연결할 때 나는 어떤 그룹에 속한다라고 지정하게 되어있음
- ⭐ 한 개의 파티션은 그룹의 한 개 컨슈머에만 연결 가능
- 컨슈머그룹 기준으로 파티션의 메시지가 순서대로 처리됨을 보장함
- 성능이 왜 좋을까?
- 파티션 파일에 대해 OS가 제공하는 페이지캐시를 사용
- Zero copy를 사용
- 브로커가 컨슈머에 대해 하는 일이 없음
- 메시지 필터, 메시지 재전송과 같은 일을 브로커가 하지 않음
- 묶어서 보내기, 묶어서 받기(batch)
- 프로듀서: 일정 크기만큼 메시지를 모아서 전송 가능
- 처리량 확장이 쉬움
- 1개 장비의 용량이 한계가 있는 경우 브로커와 파티션을 추가하면 됨
- 리플리카 - 복제
- 장애가 났을 때 이를 대처하기위해 리플리카를 사용
- 리플리카 : 파티션의 복제본
- 복제수만큼 파티션의 복제본이 각 브로커에 생김
- 리더가 속한 브로커에 장애 발생 시 다른 팔로워가 리더가 됨
- 프로듀서의 기본 흐름
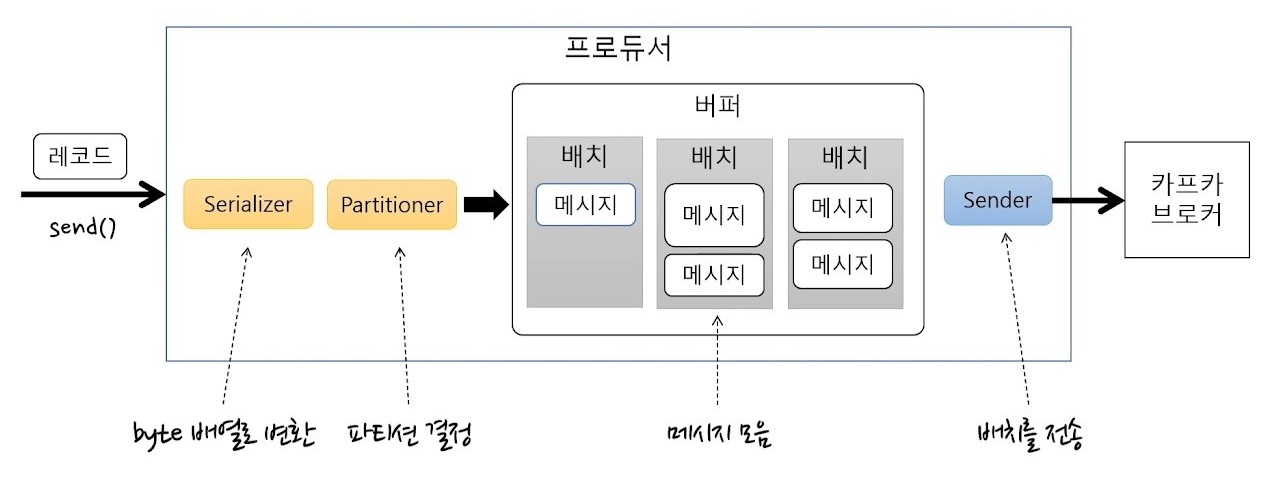
- 프로듀서가 Serializer를 이용해 바이트 배열로 변환하고, Partitioner를 통해 파티션을 결정함
- 그때 배치로 메시리지를 묶어서 저장함
- 센더가 배치들을 차례대로 가져와서 저장함
- 센더의 기본 동작
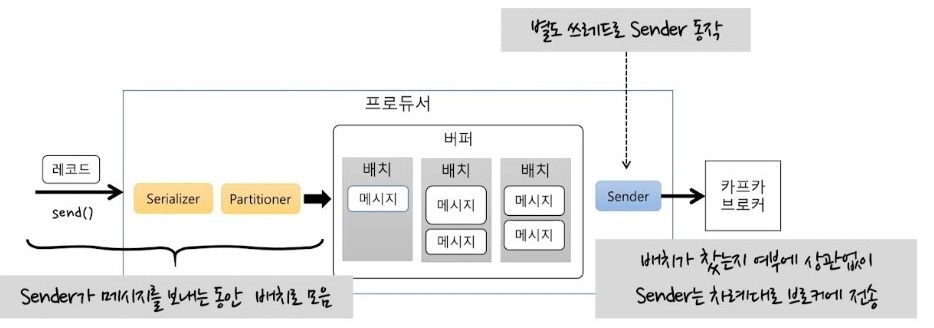
- 센더는 별도 스레드로 동작
- 배치를 차례대로 하나씩 꺼내서 카프카 브로커로 보냄
- 센더는 센더대로 배치를 꺼내서 브로커에 보내고, 센더 메소드는 계속해서 배치에 누적시킴
- 센더는 배치가 다 차지 않아도 바로 보냄
- 처리량 관련 주요 속성
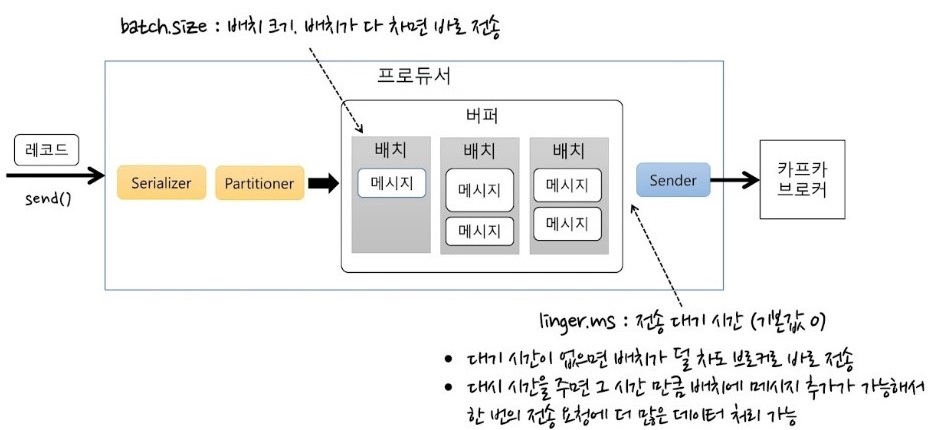
- lingers.ms : 전송 대기 시간 ( 기본값 0 )
- 대기시간이 없으면 바로 전송
- 대기 시간을 주면 시간만큼 기다렸다가 배치를 전송
- 10, 100과 같이 값을 줄 수 있음
- 전송결과 확인 안하는 경우
- 전송 실패를 알 수 없게 구현 가능
- 전송 결과를 확인해야하는 경우
- sender 메시지의 Future 사용
2.2 IBM MQ
- 가장 많이 사용되는 상용 MQ 제품으로 표준 JMS 메시징 기반으로 MQTT 프로토콜을 지원한다.
현재 내가 속한 부서에서도 DB간 동기화 시 IBM MQ를 사용하고 있다.
2.3 Apache ActiveMQ
- JAVA 기반의 JMS Queue를 지원하는 오픈소스로 MQTT, AMQP, OpenWire, STOMP 등의 프로토콜을 지원한다.
- 다양한 언어를 지원하며 클러스터링이 가능하다.
- 모니터링 도구가 없다.
- REST API를 통해 웹기반 메시징 API를 지원한다.
- Ajax를 통해 순수한 DHTML을 사용한 웹스트리밍 지원을 한다.
2.4 RabbitMQ
- 고성능을 목표로 AMQP 프로토콜을 사용하여 개발된 MQ로 Eralang OTP 기반으로 개발되었다.
- 실시간 모니터링이 용이하다
- 다양한 언어 및 OS를 지원한다
- RabbitMQ 서버 간 클러스터링이 가능하다.

