[Java] Hash Code & Hash Table
만약 Youtube에서 이미 업로드 되어있는 동영상을 다운 받아서 올릴 경우 에러가 발생한다. 전세계에 유투브 동영상 갯수도 정말 많고, 한 동영상 당 용량도 큰데 어떻게 바로 알고 이미 동영상이 있다는 메시지를 건네주는 걸까? 바로 해쉬테이블을 이용하기 때문이다.
Hash Table이란?
Key, Value로 데이터를 저장하는 자료구조 중 하나로 평균 시간 복잡도는 O(1)
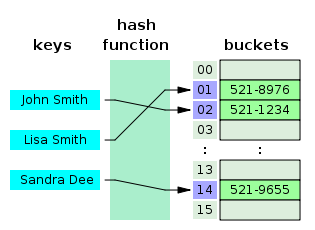
F(key) → HashCode → Index → Value
- F(key): 검색하고자 하는 키값을 입력받아서 ex) 문자열, 숫자, 파일데이터
- 해시함수: 어떤 특정한 규칙을 이용하여 입력받은 key 값으로, 그 key 값이 얼마나 큰지에 상관없이 동일한 Hash코드를 만들어준다.
- HashCode: 해쉬 함수를 입력받은 해쉬코드를
- Index: 배열의 인덱스로 환산하여
- Value: 데이터를 접근하는 방식의 자료구조 이다.
HashCode의 활용 예
암호화폐의 핵심기술인 블록체인에서도 각 사용자들의 공공장부를 비교할 때 해시코드를 이용한다.
- 블록체인: 10분 간격으로 성사된 거래 기록을 블록체인 창고에 저장하고, 지금까지 일어난 모든 거래기록을 그 서비스를 이용하는 모든 사용자들이 전자지갑을 갖고있게 하는 방식
즉 어떤 회사가 창립한 뒤 모든 거래장부를 모든 사람들이 갖게 되는 것인데, 이때 원본을 가지고 비교하게 되면 시간이 너무 오래걸리게 된다. 그래서 그 정보를 HashCode로 배포하고, 사람들은 거래장부를 HashCode로 비교하게 되는 것이다.
장점
Hash Table의 가장 큰 장점은 검색 속도가 빠르다는 것이다.
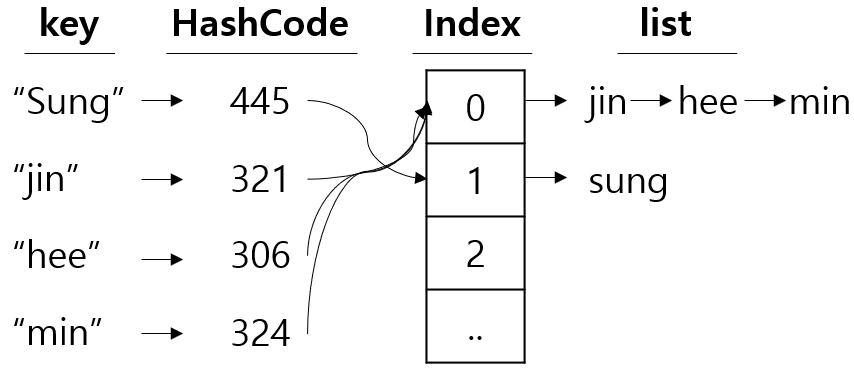 Hash 함수를 이용해서 만든 Hash Code는 정수이다. 그래서 배열 공간을 고정된 크기만큼 만들어놓고 해시코드를 배열의 개수로 나머지 연산을 하여 배열에 나눠담는다.
Hash 함수를 이용해서 만든 Hash Code는 정수이다. 그래서 배열 공간을 고정된 크기만큼 만들어놓고 해시코드를 배열의 개수로 나머지 연산을 하여 배열에 나눠담는다.
즉 코드 자체가 배열의 인덱스로 사용되기 때문에 검색 자체를 할 필요가 없고, 해쉬코드로 바로 인덱스를 찾아갈 수 있어 속도가 빠르다.
- 검색시간: O(1)
Collision(충돌)이 발생하는 경우
그런데 이때 한 인덱스에 많은 데이터가 몰려서 생성되는 경우 공간효율이 떨어지게 된다. 그래서 그 방을 나누는 규칙인 해쉬함수의 알고리즘이 너무 중요하다. 알고리즘이 좋지 않을 때 한 인덱스에 데이터가 여러개 들어가다가 충돌현상이 생기는 것을 Collison이 일어난다고 한다.
시간 복잡도
각각의 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로
평균 O(1)의 시간복잡도로 데이터를 조회할 수 있다. 하지만데이터의 충돌이 발생한 경우 Chaining에 연결된 리스트들까지 검색을 해야 하므로 최대 O(N)까지 걸릴 수 있다.
해시 함수는 때로 서로 다른 Key값으로 동일한 해시코드를 만들어내기도 한다.
- different keys → Same Code
- key 값은 문자열이고 그 가지수가 무한한데에 반해 해시코드는 정수 가짓수 만큼 밖에 제공을 하지 못하기 때문이다. 따라서 알고리즘이 아무리 좋아도 어떤 키들은 중복되는 해시코드를 가질 수 밖에 없다.
- different code → Same index
- 때로는 해쉬 알고리즘이 서로 다른 해쉬코드를 만들어 냈으나, 배열 방이 한정되어 있으므로 같은 인덱스에 배정이 되는 경우도 있다.
위 두 가지 경우를 모두 Collision(충돌) 이라고 한다.
분리 연결법(Separate Chaining)
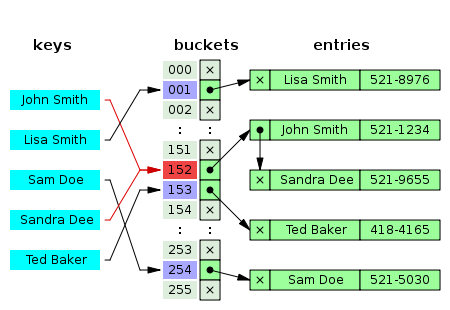
- 동일한 버킷의 데이터에 대해 자료구조를 활용해 추가 메모리를 사용하여 다음 데이터의 주소를 저장
- Java의 LinkedList를 활용하며 해시 테이블에 연결리스트에서 사용하는 Node의 객체를 저장하는 방식으로 구현 가능
- 즉, Hash Table의 셀마다 연결리스트 하나 씩 저장하도록 하고 충돌이 발생하는 데이터는 연결리스트의 다음 노드로 계속 추가해 가는 것.
- 이후에 데이터를 검색할 때에는 hash table의 인덱스를 찾은 후 셀에 연결된 리스트를 순차적으로 탐색하며 찾으려는 해쉬코드와 저장된 노드의 hashCode를 비교하는 것
구현 방법
- 고정된 크기의 해쉬 테이블을 선언한다 (필수조건)
- Collision이 생기는 경우를 대비하여 각 index에 데이터를 바로 저장하는 것이 아니라, 그 index 안에 Linked List를 선언한다. 그리고 데이터가 index에 할당될 때 마다 Linked List에 데이터를 추가한다.
- 검색요청이 들어온 경우, 해쉬함수를 통해 해쉬코드를 만든다.
- 해쉬코드를 인덱스로 환산하여 해당 index의 리스트를 반복하여 내가 찾는 데이터를 가져온다.
class HashTable{
class Node{
String key;
String value;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
LinkedList<Node>[] data;
HashTable(int size){
this.data = new LinkedList[size];
}
int getHashCode(String key){
int hashcode = 0;
for(char c : key.toCharArray()){ //각 문자의 아스키코드 값을 가져옴
hashcode += c;
}
return hashcode;
}
int convertToIndex(int hashcode){
return hashcode % data.length; //해시코드 % 배열의 사이즈
}
Node searchKey(LinkedList<Node> list, String key){
if (list == null) return null;
for(Node node : list){ //배열 방에 있는 링크드 리스트를 돈다.
if(node.key.equals(key)){ //노드의 키가 검색하는 키와 같은지를 확인
return node;
}
}
return null;
}
void put(String key, String value){
int hashcode = getHashCode(key);//key를 통해 해쉬코드를 받아온다.
int index = convertToIndex(hashcode);
System.out.println(key + ", hashcode("+hashcode+"), index(" + index+ ")");
LinkedList<Node> list = data[index]; // 배열방에 있는 번호를 이용하여 기존 배열방에 있던 데이터를 가져옴
if(list == null){//배열방이 null이면
list = new LinkedList<Node>(); //Linked List를 생성한다.
data[index] = list; //그리고 생성한 list를 배열방에 넣어준다.
}
Node node = searchKey(list, key);//그리고 배열방에 혹시 기존에 해당키로 데이터를 가지고 있는지 노드를 받아온다.
if(node == null){
list.addLast(new Node(key, value));
}else{
//동일한 데이터가 있는 경우 데이터를 대치해줌으로써 중복키 처리
node.setValue(value);
}
}
String get(String key){
int hashcode = getHashCode(key);//키로 해쉬코드를 구함
int index = convertToIndex(hashcode);//해쉬코드로 인덱스를 구함
LinkedList<Node> list = data[index];//인덱스에서 Linked List를 가져온다.
Node node = searchKey(list, key);// 링크드 리스트 안에 해당 키를 가지는 노드를 검색한다.
return node == null ? "Not found" : node.getValue();
}
}
public class Test {
public static void main(String[] args) {
HashTable h = new HashTable(3);//고정된 배열방 생성
h.put("sung", "She is pretty");
h.put("jin", "She is a model");
h.put("hee", "She is an angel");
h.put("min", "She is cute");
h.put("sung", "She is beautiful");//엎어치기
System.out.println(h.get("sung"));
System.out.println(h.get("jin"));
System.out.println(h.get("hee"));
System.out.println(h.get("min"));
System.out.println(h.get("jae"));
}
}
개방 주소법(Open Addressing)
- Open Addressing이란 추가적인 메모리를 사용하는 Chaining 방식과 다르게 비어있는 해시 테이블의 공간을 활용하는 방법. 따라서 개방주소법의 해시테이블은 hash와 value가 1:1 관계를 유지한다.
- 개방 주소법은 chaining 처럼 추가적인 메모리가 필요 없다.
- 데이터를 직접 모두 읽어오기 때문에, 포인터를 쓸 일이 없어 포인터를 사용함으로써 나타나는 오버헤드 방지 가능

위의 그림에서 John과 Sandra의 hashCode가 동일해 충돌이 일어난다. 이때 sandra는 바로 그 다음 이어있던 153 hash에 값을 저장한다. 그 다음 ted가 테이블에 저장을 하려 했으나 이미 본인의 해쉬인 153이 sandra로 채워져있음을 발견한다. 그럼 ted도 sandra처럼 바로 다음 비어있던 154 hash에 값을 저장한다.
이런식으로 충돌이 발생할 경우 비어있는 hash를 찾아 저장하는 방법이 개방주소법이다. 이때, 비어있는 hash를 찾아가는 방법은 여러가지가 있으며 대표적인 3가지를 소개하겠다.
개방 주소법의 규칙
1.선형탐색(Linear Probing)
- 해쉬 충돌 발생 시 다음 bucket 이나 몇 개의 bucket을 건너 뛰어 데이터를 삽입하는 방식
- 해당 해시 값에서 고정폭(+n)을 건너 뛰어 비어있는 해시에 저장
- 특정 해시 값 주변 버킷이 모두 채워져 있는 primary clustring 문제에 취약함
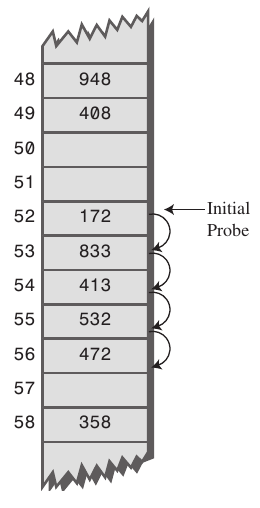
최초 해쉬코드가 52이고 고정폭이 1일 경우 4번 탐색 과정을 거쳐야한다.
- 분리 연결법은 해시 테이블의 크기를 유연하게 만들고, 개방 주소법은 해시 테이블의 크기는 고정시키되 저장해 둘 위치를 잘 찾는데 관심을 둔 구조
2.제곱탐색(Quadratic Probing)
- 해쉬 충돌 발생 시 제곱만큼 건너 뛰어 데이터를 삽이하는 방식.
- 충돌이 일어난 해시의 제곱을 한 해쉬에 데이터 저장(1^2칸, 2^2칸, 3^2칸….)
- 여러개의 서로 다른 키들이 동일한 초기 해쉬갑(아래 예시에서 initial probe)를 갖는 secondary clustering에 취약
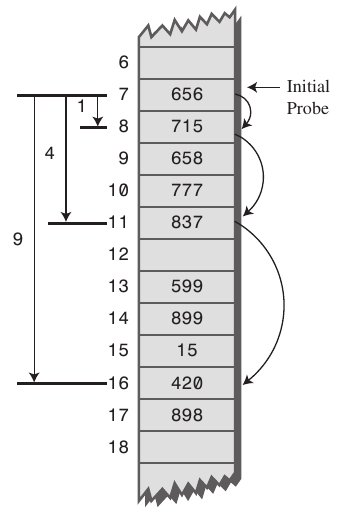
3.이중해싱(Double Hasing)
- 해시 충돌 시 다른 해시 함수를 한번 더 적용시킴
- 다른 해시함수를 한번 더 적용하여 나온 해시에 데이터를 저장
- 이중 해싱을 하면 최초 해시값이 달라지므로 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시 값이 달라져 primary, secondary clustering을 완화할 수 있음
- 장점: 또 다른 저장공간 없이 해시 테이블 내에서 데이터의 저장 및 처리가 가능
- 단점:
- 해시함수의 성능에 따라서 해시 테이블의 성능이 좌우됨.
- 데이터의 길이가 늘어나면 그에 해당하는 저장소를 마련해 두어야 함
결론
- Hash는 탐색이 빠른 배영의 장점과 삽입/삭제 시 데이터의 밀어내기 이동이 필요없는 장점을 이용해 성능을 향상시킨 데이터 저장방법이다.
- 분리 연결법(Separate Chaining): 배열과 단순 연결 리스트를 혼합하여 데이터의 삽입/삭제/탐색의 성능을 높임
- 개방 주소법(Open Addressing): 배열만을 사용하며, 저장 인덱스가 겹칠 경우 인덱스의 옆 인덱스에 저장하는 방식. 이때 옆 인덱스와의 충돌이 또 다시 일어나면 다시 옆 인덱스로 저장한다. 따라서 충돌 데이터가 많이 발생하면 성능에 심각한 문제가 발생한다는 단점이 있다.

