[Effective Java] Day 11 - Item 6, 7 :: 불필요한 객체 생성을 피하라 (2), 다 쓴 객체 참조를 해제하라
Day 11 기록 시작!
Item 6 :: 불필요한 객체 생성을 피하라 (2)
static 팩터리 메서드 사용하기
아이템 1에서 static 팩터리 메서드는 생성자에 비해 매번 새로운 객체를 만들지 않고 캐싱해둔 객체를 리턴해도 된다는 장점이 있었다.
Boolean true1 = Boolean.valueOf("true");
Boolean true2 = Boolean.valueOf("true");
System.out.println(true1 == true2);//true
System.out.println(true1 == Boolean.TRUE);//true
valueOf라는 static factory method가 위와 같이 두 번 사용되는데 두 번 다 동일한 객체를 리턴했음을 알 수 있다. 그 동일한 객체는 바로 Boolean에 있는 상수인 Boolean.TRUE이다.
무거운 객체
생성하는데 메모리나 시간이 오래걸리는 객체를 비싼 객체(Expensive Object)라고 많이 부른다. 정규표현식을 활용한 예제를 살펴보자. 문자열이 로마 숫자를 표현하는지 확인하는 코드는 다음과 같다.
// 코드 6-1 성능을 훨씬 더 끌어올릴 수 있다!
static boolean isRomanNumeralSlow(String s) {
return s.matches("^(?=.)M*(C[MD]|D?C{0,3})" + "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}
String.matches는 정규식을 받아 Pattern이라는 객체로 컴파일하는데 이 과정이 약간 오래 걸린다.
실제로 Pattern 클래스 내 compile 소스를 보자. 그럼 아래와 같이 전체 정규 표현식을 for문으로 돌면서 char 갯수만큼 반복하는 것을 볼 수 있다.
//정규표현식을 int 배열에 복사하고 object 트리를 생성할 표현식의 파싱을 호출
private void compile() {
// canonical equivalences(문자의미 및 비주얼이 정확히 일치하는 두 다른 문자열(의 연속) 처리
if (has(CANON_EQ) && !has(LITERAL)) {
normalizedPattern = normalize(pattern);
} else {
normalizedPattern = pattern;
}
patternLength = normalizedPattern.length();
// 편의를 위해 패턴을 int 배열에 복사
temp = new int[patternLength + 2];
hasSupplementary = false;
// 패턴을 종료하기 위해 double zero를 사용함
int c, count = 0;
// 모든 문자를 코드 포인트로 변환
for (int x = 0; x < patternLength; x += Character.charCount(c)) {
c = normalizedPattern.codePointAt(x);
if (isSupplementary(c)) {
hasSupplementary = true;
}
temp[count++] = c;
}
//...
}
- Code points: 문자에 부여한 고유한 숫자값. 유니코드는 원래 문자 하나 당 고유한 숫자를 부여한 일종의 표이다. 이 때 문자마다 고유한 숫자를 코드포인트라고 정의한다. 우리가 흔히 말하는 코드 값이라던가 숫자값 같은 표현이 바로 ‘코드포인트’이다.
isRomanNumeralSlow 메서드를 반복적으로 사용하면 Pattern이라는 객체를 반복적으로 만들면서 compile 메서드도 그 수 만큼 수행 되는 것이다. 즉 10번 return s.matches(regex)를 사용하면 compile 메서드도 10번 수행된다.
하지만 정규식이 변하지 않는 이상 Pattern 객체를 여러번 만들 필요가 없다. 한번만 만들어서 재사용하는 것이 좋다.
Pattern은 입력받은 정규표현식에 해당하는 유한상태머신(Finite state machine)을 만들기 때문에 인스턴스 생성 비용이 높다.
아래 java docs에 따르면, str.matches(regex) 는 Pattern.matches(regex, str) 와 정확하게 동일한 결과가 나온다고 한다.
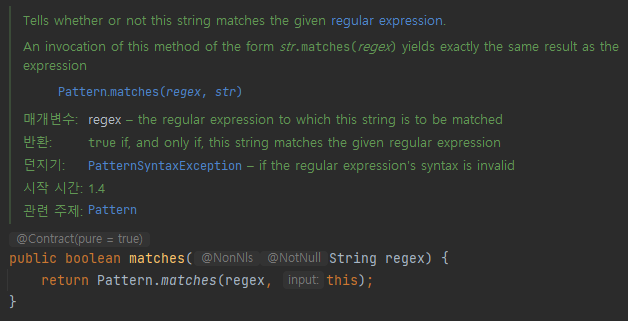
// 코드 6-2 값비싼 객체를 재사용해 성능을 개선한다.
private static final Pattern ROMAN = Pattern.compile(
"^(?=.)M*(C[MD]|D?C{0,3})"
+ "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
static boolean isRomanNumeralFast(String s) {
return ROMAN.matcher(s).matches();
}
위 코드는 Pattern 인스턴스 ROMAN을 재사용하면서, 정적 팩터리 메서드인 Pattern.compile()를 활용한 좋은 예이다.
하지만 위 코드도 문제가 있다. isRomanNumeralFast 메서드를 한 번도 호출하지 않는다면 ROMAN 필드는 쓸데없이 만든셈이 된다. 지연 초기화(lazy initialization)(아이템83)을 사용하여 불필요한 초기화를 없앨 수는 있지만 권하지 않는다. 보통 지연 초기화는 큰 성능 개선 없이 코드를 복잡하게 만든다(아이템67)
어댑터( 뷰(View) )
어떤 한 구현체를 다른 인터페이스에 맞게끔 감싸주는 역할을 하는 중간 객체이다. 즉 실제 작업은 뒷단 객체에 위임을 하고, 자신은 제 2의 인터페이스 역할을 해준다.
어댑터는 뒷단 객체만 관리하면 된다. 그 외에는 관리할 상태가 없으므로 여러개 만들 필요가 없으며 뒷단 객체 하나당 어댑터 하나씩만 만들어지면 충분하다.
Map 인터페이스는 KeySet이라는 메서드를 제공한다. 이 메서드는 map에 있는 키만 모아서 Set타입으로 리턴해준다. KeySet을 호출할 때 마다 새로운 객체가 나오는게 아니라 동일한 Map을 항상 가지고 있다가 Map에 대한 인스턴스를 넘기게 되어 있다.
그래서 Set 타입의 객체를 제거하면, 결국에 그 뒤에 있던 map 객체도 같이 변경이 된다.
public static void main(String[] args) {
Map<String, Integer> menu = new HashMap<>();
menu.put("Burger", 8);
menu.put("Kimbab", 9);
Set<String> names1 = menu.keySet();
Set<String> names2 = menu.keySet();
//이 메서드가 names1 set만 바꾸는게 아니라 동일한 다른 셋인 name2, map인 menu 객체까지 영향을 받는다.
names1.remove("Burger");
System.out.println(names2.size());//1
System.out.println(menu.size());//1
}
오토박싱
불필요한 객체를 만들어내는 또 다른 예로 오토박싱을 들 수 있다. 오토박싱은 프로그래머가 기본 타입(primitive type)과 박싱된 기본 타입을 섞어 쓸 때 자동으로 상호 변환해준다.
오토박싱은 기본타입과 그에 대응하는 박싱된 기본 타입의 구분을 흐려주지만, 완전히 없애주지는 않는다
public class autoboxing {
public static void main(String[] args) {
long start = System.currentTimeMillis();
Long sum = 0l;
for(long i = 0; i<=Integer.MAX_VALUE ; i++){
sum += i;
}
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start);//Long sum : 6448, long sum: 696
}
}
위 코드에서 sum 변수의 타입을 Long으로 만들었기 때문에 불필요한 Long 객체를 2의 31 제곱개 만큼 만들게 되고 6.45초 걸린다. 타입을 기본타입으로 바꾸면 0.7초로 약 10배 차이가 난다.
불필요한 오토박싱을 피하려면 박스타입보다는 기본타입을 사용해야 한다.
이번 아이템으로 인해 객체를 만드는 것은 비싸며 가급적이면 피해야 한다고 오해하면 안 된다. 특히 필요 없는 객체를 반복 생성했을 때의 피해보다 방어적인 복사(defensive copy)가 필요한 상황에서 객체를 재사용했을 때의 피해가 훨씬 크다.
방어적 복사에 실패하고 객체를 재사용하면 심각한 버그와 보안성에 문제가 생긴다. 객체 생성은 그저 코드 형태와 성능에만 영향을 준다.
Item 7 :: 다 쓴 객체 참조를 해제하라
메모리 직접 관리
자바에 GC(가비지 콜렉터)가 있기 때문에 메모리 관리에 대해 신경쓰지 않아도 될거라 생각하기 쉽지만 그렇지 않다. 다음 코드를 살펴보자.
// 코드 7-1 메모리 누수가 일어나는 위치는 어디인가? (36쪽)
public class Stack {
private Object[] elements;
private int size = 0;//인덱스
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
public Object pop() {
if (size == 0)
throw new EmptyStackException();
//사이즈를 먼저 줄이고 그다음 그 인덱스에 해당하는 elements를 리턴함. 왜냐? push할 때 값을 넣은 뒤 ++해서 인덱스를 하나 미리 늘려놨기 때문이다.
return elements[--size];
}
/**
* 원소를 위한 공간을 적어도 하나 이상 확보한다.
* 배열 크기를 늘려야 할 때마다 대략 두 배씩 늘린다.
*/
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size + 1);//현재사이즈의 2배정도 되는 배열을 하나 더 만들어서 용량을 늘려준다.
}
}
스택에 계속 쌓으면서 커졌다가 많이 빼면서 줄어들었다고 가정하자, 그런 경우 스택이 차지하고 있는 메모리는 줄어들지 않는다. 왜냐하면 이 스택의 구현체는 필요없는 객체들의 다 쓴 참조(obsolete reference)를 그대로 가지고 있기 때문이다.
- 즉 elements[0]에는 계속해서 그 element가 들어있다. 왜냐하면 리턴만 했지 그 elements[0]을 지워준게 아니기 때문이다. 이 배열은 계속해서 값을 넣기만 하고 있고 실제로 빼지 않는다.
가용한 범위는 size보다 작은 부분이고, 그 값보다 큰 부분에 있는 값들은 필요없이 메모리를 차지하고 있는 부분이다. 이렇게 차지만 하고 있고 앞으로 다시 쓰지 않을 부분을 다 쓴 참조라 한다.
- 여기서 가용한 범위란 실제 유의미한 값들을 element에 담고 있는 size이다.
위 코드를 다음과 같이 수정할 수 있다.
- 코드 5-1
public Object pop() { if (size == 0) throw new EmptyStackException(); Object result = elements[--size]; elements[size] = null; // 다 쓴 참조 해제 return result; }
스택에서 꺼낼 때 그 위치에 있는 객체를 꺼내준 다음 그 자리를 null로 설정해서 다음 가비지 컬렉터가 발생할 때 참조가 정리되게 한다. 실수로 해당 위치에 있는 객체를 다시 꺼낼려고 하면 nullPointerException이 발생할 수 있긴 하다. 하지만 미리 null 처리 하지 않았다면 잘못된 객체를 돌려주었을 테니 익셉션이 발생하는게 낫다. 프로그램 오류는 가능한 조기에 발견하는 것이 좋다.
그렇다고 모든 객체를 다 쓰자마자 일일히 null로 설정하는 코드는 작성하지 말자. 객체 참조를 null처리 하는 일은 예외적인 경우여야 한다. 다 쓴 참조를 해제하는 가장 좋은 방법은 그 참조를 담은 변수를 유효 scope 안에서만 사용하는 것이다. 로컬 변수는 그 영역이 넘어가면 쓸모가 없어져서 정리가 되기 때문이다.
아래 소스코드에서 age라는 변수는 scope이 pop이라는 메서드 안에서만 한정되어 있다. pop 메서드 밖에서는 무의미한 참조 변수가 되기 때문에 gc에 의해서 정리가 된다. 그러므로 이런 경우 매번 null로 만들지 않아도 된다.
Object age = 27 ;
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // 다 쓴 참조 해제
age = null;
return result;
}
변수의 범위를 최소가 되게 정의했다면 자연스럽게 gc에 의해 정리 될 것이다. 하지만 코드 5-1처럼 size라는 멤버 변수와 elements를 쓰는 경우는 자연스럽게 정리 되지않는 예외적인 상황이라 명시적으로 null로 설정하는 코드를 써줬다.
그럼 언제 참조를 null처리 해줘야할까? 바로 자기 메모리를 직접 관리할 때이다. Stack 구현체처럼 elements라는 배열을 직접 관리하는 경우에 GC는 어떤 객체가 필요없는 객체인지 알 수 없다. 오직 프로그래머만 elements에서 가용한(size보다 작은) 부분과 필요없는(size보다 큰) 부분을 알 수 있다. 따라서, 프로그래머는 해당 참조를 null 처리하여 GC한테 필요 없는 객체임을 알려야 한다.
자기 메모리를 직접 관리하는 클래스는 프로그래머가 항시 메모리 누수를 조심해야한다.
캐시
어떤 Object라는 키에 대해 아래와 같이 캐싱을 한다고 하자.
Object key1 = new Object();
Object value1 = new Object();
Map<Object, Object> cache = new HashMap<>();
cache.put(key1, value1);
그런데 이런 경우가 있을 수 있다. cache 안에다가 데이터를 쌓아놨는데 이 cache를 비워야하는 시기를 놓치는 경우가 있다. 캐시의 키인 key1이 없어지면 value1 값은 무의미해지는데 그런 경우 자동으로 해당 엔트리를 비워주는 weakHashMap이라는게 있다.
- 매핑(mapping) 또는 엔트리(entry): 키와 값으로 구성되는 데이터 (from 자바 공식 문서)
public class Item7App { public static void main(String[] args) { WeakHashMap<String, Object> map = new WeakHashMap<>(); String key1 = new String("key1"); String key2 = new String("key2"); map.put(key1, "test 1"); map.put(key2, "test 2"); key1 = null; // key1에 대한 참조가 사라졌을 경우에 GC 대상이 된다. System.gc(); map.entrySet() .stream() .forEach(System.out::println);//출력: key2=test 2 } }
WeakHashMap 주의사항
- String을 literal 방식으로 할당할 경우 gc의 대상이 되지 않는다.
(참조 : Java - Collection - Map - WeakHashMap (약한 참조 해시맵) - 조금 늦은, IT 관습 넘기 (JS.Kim))
또는 특정 시간이 지나면 캐시값이 의미가 없어지는 경우에 아래 2가지 방법을 통해 캐시를 비우는 작업을 해줘야 한다.
Scheduled ThreadPoolExcutor백그라운드 스레드를 활용하거나- 캐시에 새 엔트리를 추가할 때 부수 작업으로 수행하는 방법
- ex)
LiknedHashMap클래스는removeEldestEntry메서드
- ex)
리스너(listner) or 콜백(callback)
클라이언트가 콜백을 등록만 하고 명확히 해지하지 않는다면, 콜백은 계속 쌓여갈 것이다. 이것 역시 weakHashMap으로 저장하면 가비지 컬렉터가 즉시 수거해간다.
결론
메모리 누수는 발견이 쉽지 않기 때문에 수년간 시스템에 잠복하고 있을 수도 있다. 코드리뷰나 heap profiler같은 디버깅 도구를 사용하여 찾아야한다. 따라서 이런 문제는 예방법을 익혀두고 미연에 방지하는 것이 좋다.

