[Database] DB 샤딩(Sharding)이란 무엇인가?

Database를 확장할 수 있는 방법은 하드웨어 확장, Replica 추가, 그리고 Sharding까지 여러가지가 있다. 그리고 이 글에서는 Database Sharding이란 무엇인가?에 대해 그 개념을 정리하고자 한다.
요즘은 점점 데이터가 쌓여가면서 대용량 데이터로 인해 이슈를 겪는 곳이 많은 것 같다. 내가 속한 부서에서도 문제 없이 정상적으로 조회되던 화면이 1년동안 2,400만건의 데이터가 쌓이면서 조회가 되지 않는 이슈가 발생한 적이 있다.
이렇게 쌓이는 대규모 데이터는 DB 시스템의 과부하로 용량의 한계를 맞이하게 한다. 이때 관리자들은 시스템 업그레이드를 고려하는데 이때 시스템 업그레이드는 위에서 첫 번째 방법으로 말했던 하드웨어 확장을 의미한다.
즉 장비를 고사양으로 전환해 기존 시스템의 처리 용량을 증대시키는 방법이다. 이는 Scale-up이라고도 한다. 여기서는 이 방식을 사용하여 DB 자원을 증설한다.
Scale-up the Hardware
이 방식은 기존에 사용하는 장비를 업그레이드 하는 것이기 떄문에 기존 장비 사양에 따라서 증설 계획이 결정된다. 하지만 보통 DB는 최초 구매할 때 부터 고사양으로 구매하는 것이 일반적이기 떄문에, 이렇게 좋은 성능의 DB에서 더 좋은 장비를 구매한다는건 비용적으로 많은 부담을 안길 수 있으며 약간의 제약이 따른다.
Sharding
엥 그럼 비용도 아끼면서 어떻게 장비를 활용하는 것이 대용량 데이터베이스를 저장할 수 있단 말인가! 이러한 문제점을 해결하기 위해서 DB 시스템은 소프트웨어적으로 DB를 분산시켜 처리할 수 있는 구조를 만들었는데, 이러한 기술 중 하나가 우리가 오늘 배우려고 하는 샤딩(Sharding)이다! 샤딩은 2가지 종류가 있는데 아래 2개로 나뉘어 진다.
- DB가 저장하고 있는 테이블을 테이블 단위로 분리하는 방법
- 테이블 자체를 분할하는 방법
<가정> 우리가 사용하는 DB에 총 5개의 테이블이 있다. 근데 5개의 테이블에 대용량 데이터가 갑자기 몰려 시스템 사양을 초과헀다. 이를 샤딩하기 위해 한 대의 DB 시스템을 2대로 증설하려 한다.
여기서 첫 번째 방법인 테이블 단위로 분리하는 방법(a)을 사용하는 경우를 생각해보자. 총 5개의 테이블에서 첫 번째 장비에는 테이블 3개, 두 번째 장비에는 테이블 2개로 분리할 수 있다. 두 번째 방법인 테이블 자체를 분할하는 방법(b)은 총 5개의 테이블을 모두 반반씩 쪼개어 두 개의 장비에 나누어 저장하는 방법이다.
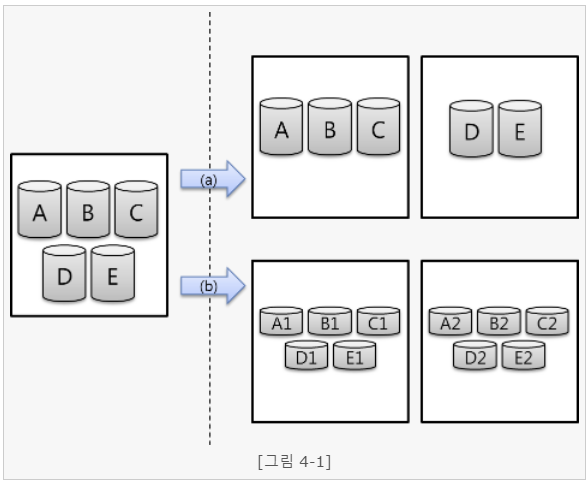
좌측과 같이 한 곳에 저장되어 있던 테이블을 두 개 이상의 shard로 데이터를 분리하는 경우, DB 시스템은 사용자 Query에 따라 검색되어야 할 데이터가 어떤 Shard에 위치하고 있는지 위치 정보를 관리하는 모듈이 필요하다.
- 중개자(broker): 샤딩된 데이터의 위치 정보를 관리하는 모듈. 질의를 분석하여 Shard를 선택하고, 응답에 대한 결과를 전달하는 역할을 담당
예시
피자를 생각해보자. 난 한 조각씩 잘려진 피자를 갖고 있고 이 조각 피자를 친구들에게 공유하려고 한다. 데이터 분할이라고도 하는 샤딩은 피자 조각을 공유하는 것과 동일한 개념이다. 기본적으로 큰 데이터 세트를 더 작은 덩어리(논리적 샤드)로 분할하고 이러한 덩어리를 다른 머신/데이터베이스 노드(물리적 샤드)에 저장/배포하는 데이터베이스 아키텍처 패턴이다.
여기서 각 덩어리/파티션은 “샤드”로 불리며 각 샤드는 원본 데이터베이스와 동일한 데이터베이스 스키마를 가진다. 우리는 각 row가 정확히 하나의 샤드에 나타나는 방식으로 데이터를 배포한다. 이것은 애플리케이션의 확장성을 향상시키는 좋은 메커니즘이다.
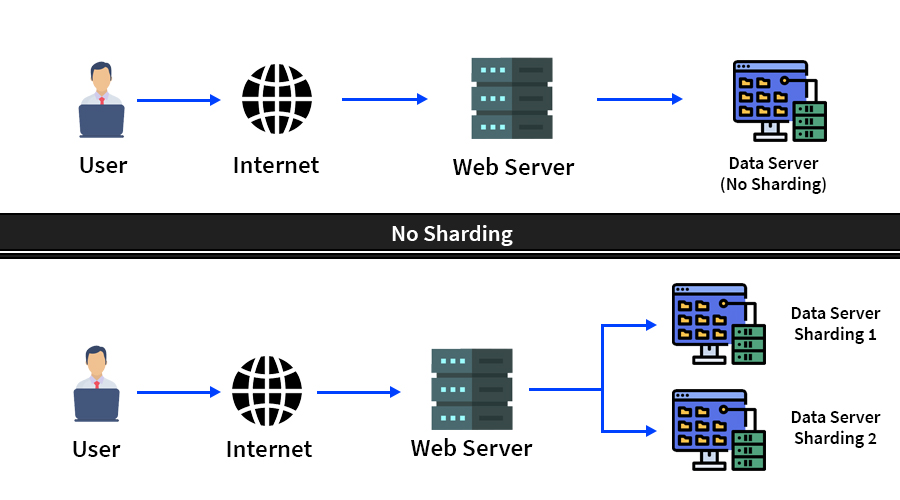
데이터베이스 샤드는 자율적이다. 동일한 데이터나 컴퓨팅 리소스를 공유하지 않는다. 그러나 어떤 경우에는 특정 테이블을 각 샤드로 복제하여 참조 테이블로 사용하는 것이 더 적합할 떄도 있다.
Sharding System의 구조
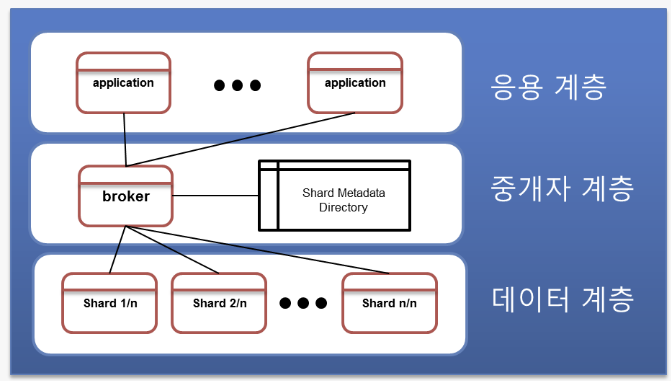
위 그림은 Sharding System의 구조를 보여준다. 이 시스템은 크게 응용계층, 중개자 계층, 데이터(서버 또는 샤드) 계층으로 구성된다.
- 응용계층
- 데이터에 접근하기 위해 중개자를 통해 모든 데이터 입출력을 진행
- 응용은 샤딩된 DB 시스템의 자세한 구조를 알 필요 없이 하나의 추상화된 DB가 존재하는 것 처럼 느끼게 됨
- 중개자 계층
- 응용계층과 데이터 계층 사이에 위치
- 샤딩 시스템의 가장 핵심적인 부분
- 샤드 메타 정보(Shard Meta data)를 저장하여 중개자로부터 전달된 질의를 분석
- 적절한 샤드에 명령을 수행하고 그 결과를 응용에 전달함
- 데이터 계층
- 여러개의 샤드(또는 서버)로 구성됨
- 각각의 샤드는 일반 DB 시스템과 동일한 역할을 담당
중개자 계층이 저장하는 샤드 메타 정보는 분할을 결정하는 정책에 따라 아래 3가지로 분류된다.
- 형태에 따른 분류
- 독립된 쿼리가 보장되는 시스템에서 RDB를 분할하는 방법에 효과적임
- Key 기반 분류
- 자동 샤딩 시스템에 잘 적용됨
- Look-up 테이블 기반 분류
- Scale-out 중심의 분산 DB에 적합
위 3가지 Shard 전략 모두 장단점을 갖고 있으므로 어떤 전략이 무조건 적으로 좋다라고 말할 순 없다. 각각의 장단점을 잘 파악하고 어떤 전략을 사용할지 결정해야 한다.

